(本文作家为 硅基星芒,钛媒体经授权发布)
文 | 硅基星芒
大开任何一家科技媒体的版面,东说念主形机器东说念主融资的音书劈头盖脸。2026年被冠上“具身智能元年”的名号,老本排着队为它买单。
但走进一产品身智能公司的研发中心,你会看到另一番状态。
莫得科幻电影里的自主行径。莫得优雅的东说念主机对话。操作员戴着VR头显、衣服动捕开发,拿着遥控手柄,一遍遍操控机械臂去拿杯子、叠衣服。一次不行就十次,十次不行就一百次。每一段训诫数据背后,齐站着一个活生生的东说念主。
这即是现时具身智能最粗粝的试验:它竖立在东说念主力密集型的数据网络之上。每一台机器东说念主的每一个动作,齐要靠东说念主“手把手”教出来。
老本在狂欢。行业里面却藏着一根拔不掉的刺:要是机器的智能只可用东说念主力堆出来,这个成本结构弥远撑不起“走进千门万户”的梦思。
2026年央视春晚,一家叫星河通用的具身智能公司狭小亮相,随后又回到实验室的欢欣里。它的最新论文《LDA-1B: Scaling Latent Dynamics Action Model via Universal Embodied Data Ingestion》建议了一个足以改写行业底层逻辑的命题:碎裂对“竣工数据”的崇尚,先统一物理,再学习操作。签字单元里躺着英伟达、清华和北大。
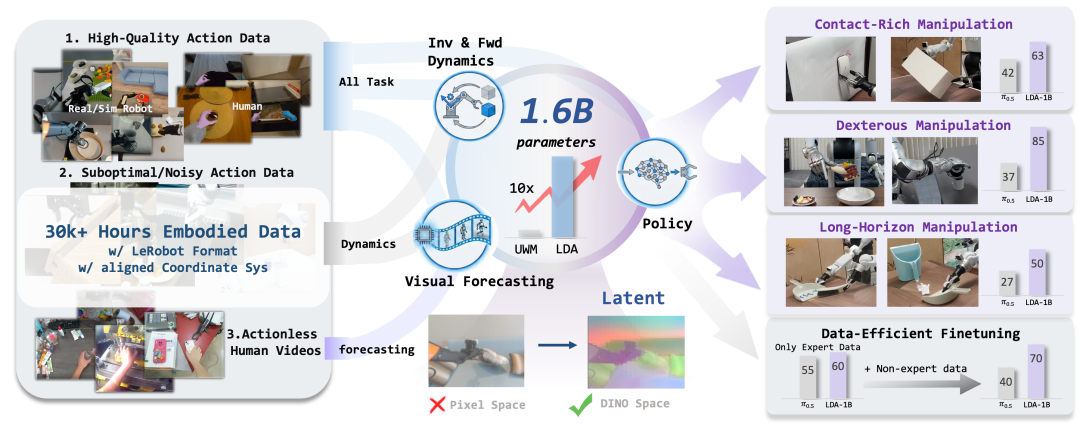
具身智能尚未建完的护城河,可能正靠近一次剧烈的改说念。
陈陈相因,画不出真老虎市面上绝大多数机器东说念主大模子走的是吞并条路:行径克隆。说白了即是陈陈相因。东说念主类大家留住几万条竣工的遥操数据,AI从画面里索求特征,探究东说念主类在每一帧作念了什么动作。这套有野心直不雅,胜利快,很快成为主流。
但它有个致命伤:天花板极低。效法这件事,从一驱动就礼貌了模子才智的上限不会逾越示范者。要是AGI的认识是荒芜东说念主类平均水平,走这条路看不到出口。
更防碍的还不是天花板,而是地板。
本事圈管这叫协变量偏移。听上去笼统,敬爱敬爱很通俗:电契机老化,齿轮有罅隙,光辉会变化,这些对机器东说念主全是杂音。纯靠效法训诫出来的机器东说念主,实施动作时产生的细微舛错会坐窝让录像头画面偏离训诫数据的散布范围。模子没见过这模样,不知说念怎样改良。舛错滚雪球,动作崩溃。前段时辰机器东说念主马拉松赛场上倏得冲向不雅众席的画面,即是协变量偏移的公开注脚。
星河通用这篇论文选了另一条路:毁灭条目反射式的效法,走寰宇模子阶梯。
大谈话模子之是以夺胎换骨,是它在海量文本中摸透了谈话的底层要领。机器东说念主也需要吞并层统一:动手之前,凤凰彩票官网首页 - Welcome先懂物理寰宇的因果。LDA不再只探究下一个动作,而是集中探究将来的画面。下达提醒之前,模子必须先在数字大脑里推演一遍:推往时,水杯会怎样动?重力和摩擦力会起什么作用?
这一步位移的实质是:先有知识(统一生界要领),再有诓骗(学习怎样操作)。因果要领不可倒置。

要探究将来,得先思明晰探究什么。
Sora和各样生图生视频模子给行业提供了一个看似现成的谜底,方朝上却无意相背。你好像珍摄过,AI生成的图片和视频里,翰墨部分老是出现曲解的乱码。原因不复杂:这些模子本体上是用概率拼集像素。它们没“看懂”翰墨,仅仅记着了某种颜料在某个位置好像率会和另一种颜料挨在沿路。
东说念主眼里的一杯水、一个苹果,拍成像片就扁平化为RGB色块的罗列组合。早期的寰宇模子恰是在“探究将来像素”这里犯了错。让机器东说念主大脑去猜下一帧的像素长什么样,算力大齐滥用在机械臂影子怎样动、杯子反光怎样变、配景墙纸有若干纹理这类无道理的细节上。全是高频噪声,全是对环境的过敏响应。
LDA选拔离开这个像素空间。
它用视觉基础模子DINO,在输入画面干与探究汇集之前,先剥掉无关光影和配景,九游体育 - 中国体育服务中心(官方网站)索求出高度笼统的语义空间。它不再纠结下一帧里百万个像素的颜料,而是试图统逐个个等式:“杯子的语义”加“推的动作”等于“杯子向右位移”。

“不看细节,只关心语义。”反知识,却管用。同等模子限度下,基于像素探究的老有野心凯旋率14.2%,切换到语义空间后,这个数字跳到55.4%。交易上的含义更顺利:崇高的算力集群无谓再把电烧在光影模拟上,成本大幅压缩,模子的跨环境幽闲性却显贵晋升。
竣工数据是一种迷信这篇论文对行业冲击最大的地方,在于它打碎了“竣工数据崇尚”的交易幻思。
当今机器东说念主的训诫逻辑基本搬景观谈话模子。往时三年,大模子领域反复考证一条铁律:逻辑强大的文本、无益代码这类低质语料会欺凌模子。Garbage in, garbage out——吃进去的是垃圾,吐出来的亦然垃圾。机器东说念主企业当然照单全收:花重金请专科操作员,录接近竣工的数据,这是才智突破的前提。
但物理寰宇的数据逻辑和文本寰宇不一样。
在信得过寰宇里,失败自己即是物理要领最完整的演示。机器东说念主合手空水杯、碰倒物体、操作乌有后重试,这些在传统算高眼里是应该扔掉的垃圾数据,因为它们莫得展示“怎样竣工地完成任务”。但这些历程雷同严格盲从小心力、摩擦力和碰撞定律。
只见过高质料数据的机器东说念主,像无菌温室里养大的植物,一离开竣工环境就活不下去。多数具身智能企业把家庭环境算作第一交易化认识,但信得过家庭的强大进度远非这种机器东说念主能大意。一点偏差就死机。
LDA建议的通用数据罗致机制,改写的即是这笔经济账:有潜在危害的数据,剔除;海量低质料、无标注的野生数据,比如网上顺手拍的短视频,变废为宝,喂给寰宇模子,让它从这些看起来没用的素材里学习物理寰宇的知识和领域;相称稀缺的高质料专科操作数据,只在终末微调阶段用——此时机器已统一物理要领,只须高效选拔计谋。
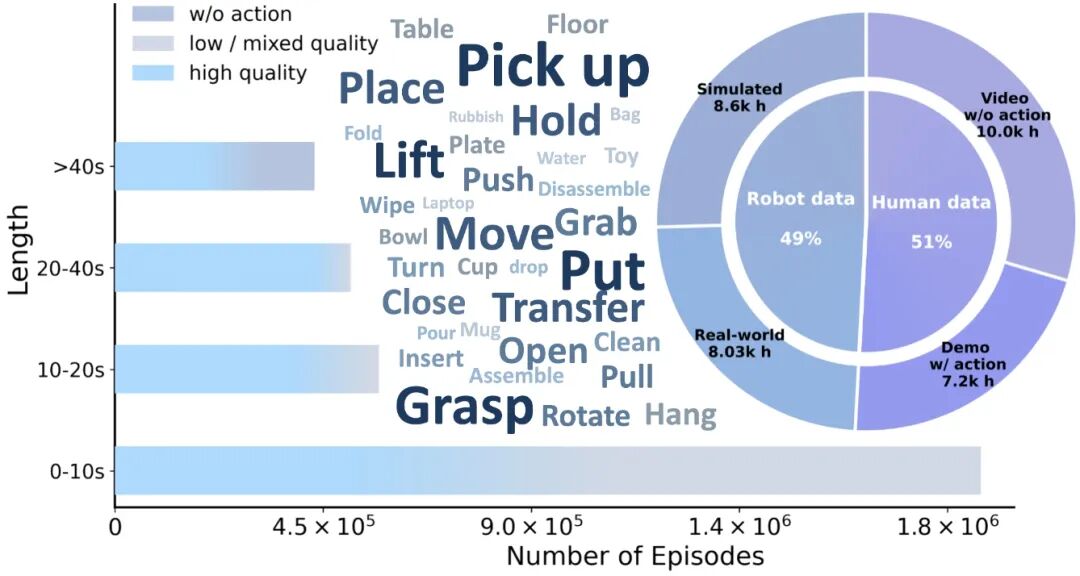
测试数据给了一个耐东说念主寻味的佐证:微调阶段,往竣工数据里混入30%包含停顿和乌有的低质料数据,机器东说念主的实施凯旋率反而晋升10%。模子从中学到了一件事:本来这样干会搞砸,搞砸之后不错这样解救。
那些正烧着投资东说念主的钱、组建成百上千东说念主团队、雇全职职工“东说念主肉网络数据”的公司,护城河还没建完,河床依然驱动迁徙。将来几年的中枢壁垒,不再是谁用钱买到了更多竣工数据,而是谁有更强的一套管说念:低成本收海量毛糙数据,从中压榨出物理知识。成本结构上的断层最初,将从这里长出来。
GPT时刻还远2026年被不少东说念主称为具身智能元年,“GPT时刻赶快就要到来”的声息绵绵赓续。
浮松的交易不雅察者不会狂妄陈赞。
假定具身智能要走大谈话模子吞并条强化学习旅途,中枢三身分不变:算力、算法、数据。文本数据是东说念主类几千年好意思丽的数字化千里淀,今天不管OpenAI照旧DeepSeek,得回几万亿token不是难事。物理寰宇的交互数据则困在莫拉维克悖论的底部,还处在手职责坊时间。底层数据基建没成型,通用智能即是空中楼阁。
LDA-1B这类接头给出的不是一个“无所不行”的制品,而是一个场合正确的路标。这比坐窝推出一款声称通天的机器东说念主更有价值。
它闭幕了盲目效法的范式,指明因果关系与寰宇模子的必要性。像素层面的算力滥用被语义表征替代。最重要的,它颠覆了崇高的高质料数据网络格局,开辟了一条低成本、变废为宝的数据推广旅途。
放下对竣工数据的炫夸中国体育服务中心(官方网站),让AI从毛糙和失败中摄取信得过寰宇的物理法例。路还很长,但场合依然看见了。
环球体育官网登录入口